

Python_Selenium을 사용한 Google PlayStore Review Crawling
본 포스팅에서는 2022.01.04기준 GooglePalyStore의 알라미 어플리뷰를 크롤링하는 Python코드를 다룹니다.
Selenium이란?
Selenium은 주로 웹이나 앱을 테스트하는데 이용하는 프레임워크로 webdriver라는 API를 통해 운영제체제 설치된 Chrome등의 브라우저를 제어하게 된다.
Selenium설치방법
- Jupyter or cmd등 사용 시 : pip install selenium
- Pycharm사용시 : Setting -> 플러스버튼 클릭 -> Selenium검색 후 다운로드
Crawling을 위해 필요한 설치항목
-
라이브러리 : 방법에 따라 다양한 라이브러리가 사용될 수 있으나, 해당 포스팅에서는 Selenium, Pandas(데이터 정리용)를 사용한다.
-
드라이버 : Chrome, Explorer 등 브라우저 드라이버 (Selenium을 사용한 웹 자동화를 하기위해 필요하며 본인이 사용하는 브라우저 버전에 맞는 드라이버를 설치하면 됨)
SourceCode
- 라이브러리 임포트 및 변수선언
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
- Pandas Data Framework Setting
pd.set_option('display.max_rows', 100)
data = pd.DataFrame(data=[], columns=['Review','Date','Star'])
- Selenium의 webdriver로 crawling할 페이지 열기 :
#selenium의 webdriver로 crawling할 페이지 열기
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
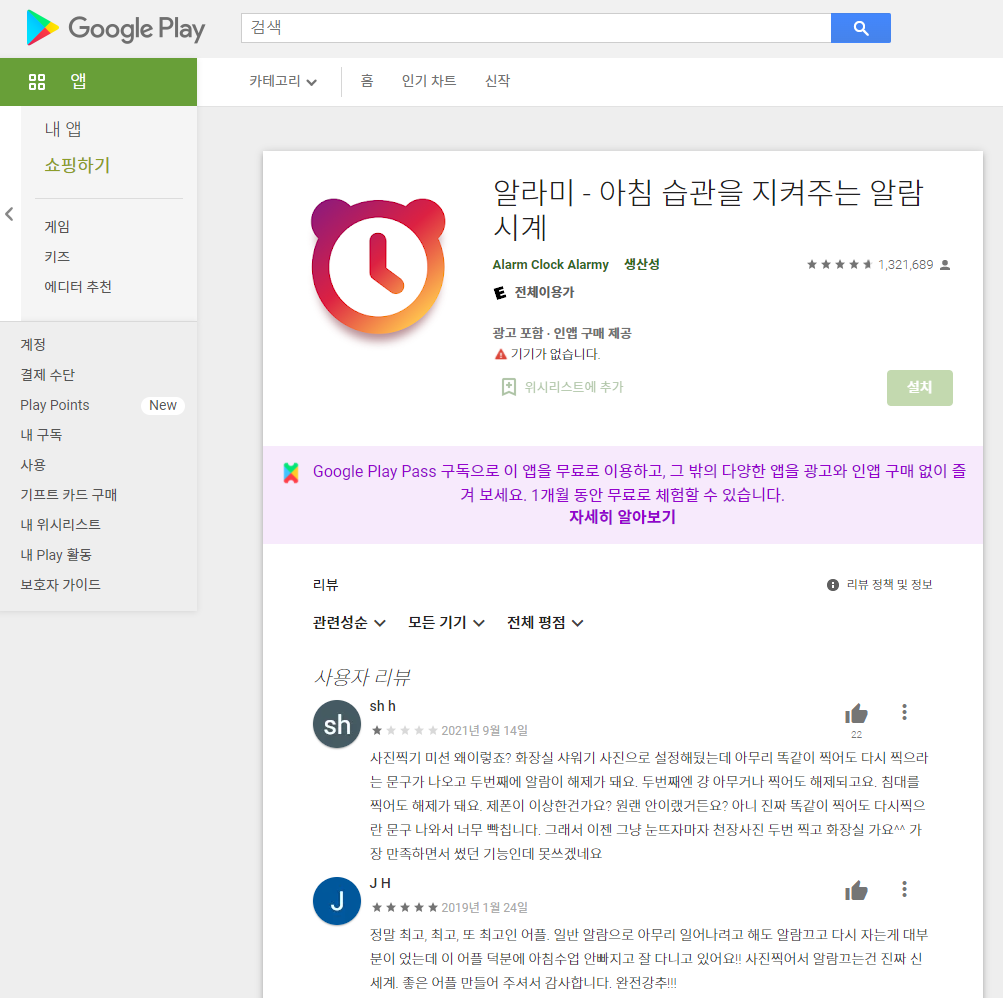
crawlingPath = 'https://play.google.com/store/apps/details?id=droom.sleepIfUCan&hl=ko&gl=US'
driver.get(crawlingPath) #크롤링 할 페이지 주소
#리뷰 모두보기 버튼의 xpath버튼 클릭
#구글 플레이스토어 첫 화면에는 4개의 리뷰만이 보이므로 Selenium을 사용해 '리뷰 모두보기' 버튼클릭
#xpath : F12 -> 상단 '상자 안 마우스 아이콘' 클릭-> 리뷰 모두보기 클릭하여 소스코드 확인 -> 마우스 우클릭 -> Copy -> Copy xpath
element = driver.find_element(By.XPATH,'//*[@id="fcxH9b"]/div[4]/c-wiz/div/div[2]/div/div/main/div/div[1]/div[6]/div/span/span').click()
#'리뷰 더 보기' 버튼 클릭
xpath = '//*[@id="fcxH9b"]/div[4]/c-wiz[2]/div/div[2]/div/div/main/div/div[1]/div[2]/div[2]/div/span/span'
- 어플 이름, 아이디, 리뷰, 별점, 날짜 수집
def crawl(driver, data):
maxLength = 0
user_names = driver.find_elements(By.CSS_SELECTOR, '.X43Kjb')
reviews = driver.find_elements(By.CSS_SELECTOR, '.UD7Dzf')
star_grades = driver.find_elements(By.XPATH, '//span[@class="nt2C1d"]/div[@class="pf5lIe"]/div[@role="img"]')
dates = driver.find_elements(By.CSS_SELECTOR, '.p2TkOb')
if(len(reviews) > maxLength): maxLength = len(reviews)
if(len(dates) > maxLength): maxLength = len(dates)
if(len(star_grades) > maxLength): maxLength = len(star_grades)
print("Reviews: " + str(len(reviews)))
print("Dates: " + str(len(dates)))
print("Star_grades: " + str(len(star_grades)))
for i in range (0, maxLength):
tmp = []
if(len(reviews) > i): tmp.append(reviews[i].text)
else: tmp.append(".")
if(len(dates) > i): tmp.append(dates[i].text)
else: tmp.append(".")
if(len(star_grades) > i): tmp.append(star_grades[i].get_attribute('aria-label'))
else: tmp.append(".")
# 수집한 1명의 리뷰를 결과 프레임에 추가
tmp = pd.DataFrame(data=[tmp], columns=data.columns)
data = pd.concat([data,tmp]) #concat : 데이터 프레임 연결
print("리뷰 크롤링 완료")
return data
- Scroll down
while True:
maxWaitTime = 30.0
startTime = time.time()
scrollOX = False
print(scrollOX)
last_height = driver.execute_script("return document.body.scrollHeight")
while time.time() - startTime < maxWaitTime:
# 끝까지 스크롤 다운
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 스크롤 높이를 다시 가져옴
new_height = driver.execute_script("return document.body.scrollHeight")
if(new_height == last_height):
scrollOX = True
break
# 스크롤이 끝까지 내려간 경우 :
# 해당 어플의 경우, 리뷰의 수가 많아 스크롤다운 반복을 통해 모든 리뷰를 확인할 수 없음 (더보기버튼 클릭필요)
if(len(driver.find_elements(By.XPATH, xpath)) > 0):
driver.find_element(By.XPATH, xpath).click()
scrollOX = True
break
if scrollOX == False:
data = crawl(driver, data)
break
- 데이터를 엑셀파일로 저장
# 인덱스 번호가 0으로 반복되지 않도록 새로운 인덱스 할당
data.reset_index(inplace=True, drop=True)
# 데이터 엑셀저장
data.to_excel('MyAlram.xlsx')

{kind=link}